















ABK-GOFAI: Abak Evolution Backgammon をプレイするための Good Old-Fashion Artificial Intelligence。
ニューラルネットワークの助けなしでは、Abak の人工知能(AI)開発は困難な課題であり、やがて見かけ上の限界に達しました。それでも開発プロセスは楽しく、現在でも「easy」「normal」「advanced」レベルで稼働しています。これは、その仕組みと作り方についての投稿です。
フェーズ 1、GOFAI PHP
Abak 初の AI バージョンは PHP で書かれ、「out of memory」エラーでシステムを落とすと判断されましたが、C++ 版への道を切り開きました。AI をいったいどう作るのかを自分なりに探るための試作遊び場だったのです。初めてそれを Web サーバーに接続して動かしたとき(つまり実際にそれと対戦したとき)、手を選ぶのに長い 15 秒もかかりました。そしてサーバーが自力で動くのを見た瞬間、私は大興奮して少し踊ったかもしれません。たぶん。
フェーズ 2、GOFAI C
こうして AI の C/C++ 版、つまり本番環境に初めて投入された愛しの GOFAI エンジンが、PHP の灰の中から誕生しました。これは何千もの局面に対して 29 個の解析アルゴリズムをナノ秒単位で走らせ、流れは次のようになります:
- 盤面位置とサイコロの組を与える。
- 状態を計算する。
- 可能な移動をすべて取得する。
- 各移動を分析してスコアを与える。
- 「最良」のスコアを選ぶ。
以下がそのプロセス図です。

これは主に 4 つの関数で構成されています:
- Get Actions(有効な移動を計算する):
盤面位置とサイコロの出目が与えられると、有効な移動をすべて計算します。
有効な移動数は 0 から数万に及ぶことがあります。
これをどの言語で書いても、私は不必要に再帰的なアプローチを取ってしまい、デバッグはとても難しくなるのですが、その美しさに抗えません。コードは数百行程度ですが、書くのに何週間もかかり、その後 C へ移植するのにもさらに何週間もかかりました。
- Get state(盤面状態を計算する):
盤面位置が与えられると、意味的な状態を計算します。かなり名前の通りです:
- 開始局面
- 中盤
- 望みなきランニング
- 望みあるランニング
- 終盤
- ホーム突入
-
Analyse Movement(盤面位置のスコアを計算する):
これは圧倒的に最も大規模なアルゴリズムです。盤面の特徴を分析し、それぞれがスコアを返します。そして、先に計算した状態に基づいて係数を適用し、ゲーム状態に応じて分析の各側面に異なる重みを与えます。
AI は最初 8 個のアルゴリズムで始まり、最終的に 29 個まで増えました。いくつか挙げると:
- 列の高さ
- ヒットされるリスク
- Druid に捕まるリスク
- ホームの強さ
- 脱出の支点
- バー上のチェッカー
- 安全なチェッカー
これらの多くは当初とても基本的なものだったか、あるいは存在すらしていませんでした。
時間をかけて機能を追加し、係数を微調整していきました。
-
Select Action(「最良」の移動を選ぶ):
最高スコアだけを欲しいのであれば、このアルゴリズムは比較的単純です(Advanced レベルがそうです)。
Normal と Easy レベルでは、ベストアクションのリストからランダムに手を選びます。そのリストの大きさ(または弱い手への許容度)はレベルによって決まります。
C のおかげでこのエンジンは猛烈に速く、今後も私はこれを主要な get-actions 関数として使い続けるでしょう。
フェーズ 3、GOFAI C チューンアップ
このエンジンをデバッグし、問題を切り分け、微調整するために、私は意思決定プロセスを監視する多くのツールを構築しなければなりませんでした。ニューラルネットワークと違って、こちらの各判断は監査可能なので、それが唯一の救いでした。
このプロセスは楽しかったものの、ひどく遅かったです。私は CPU 相手に何度も対戦し、悪い手を見つけるたびにツールへ戻って何が悪かったのかを確認しました。ときにはアルゴリズムの修正、係数の調整、新しい分析モデルの構築へ進みました。そしてときには――これは素晴らしいことでしたが――自分の Abak Evolution 戦略そのものを見直すきっかけにもなりました。
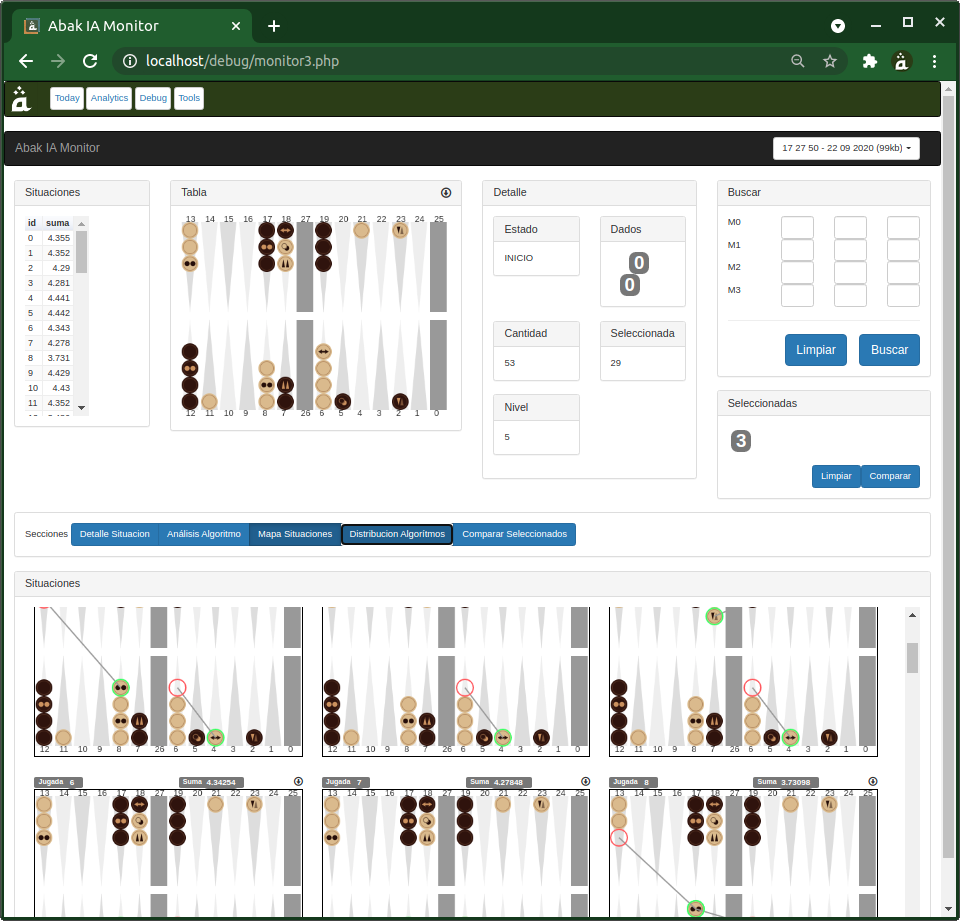
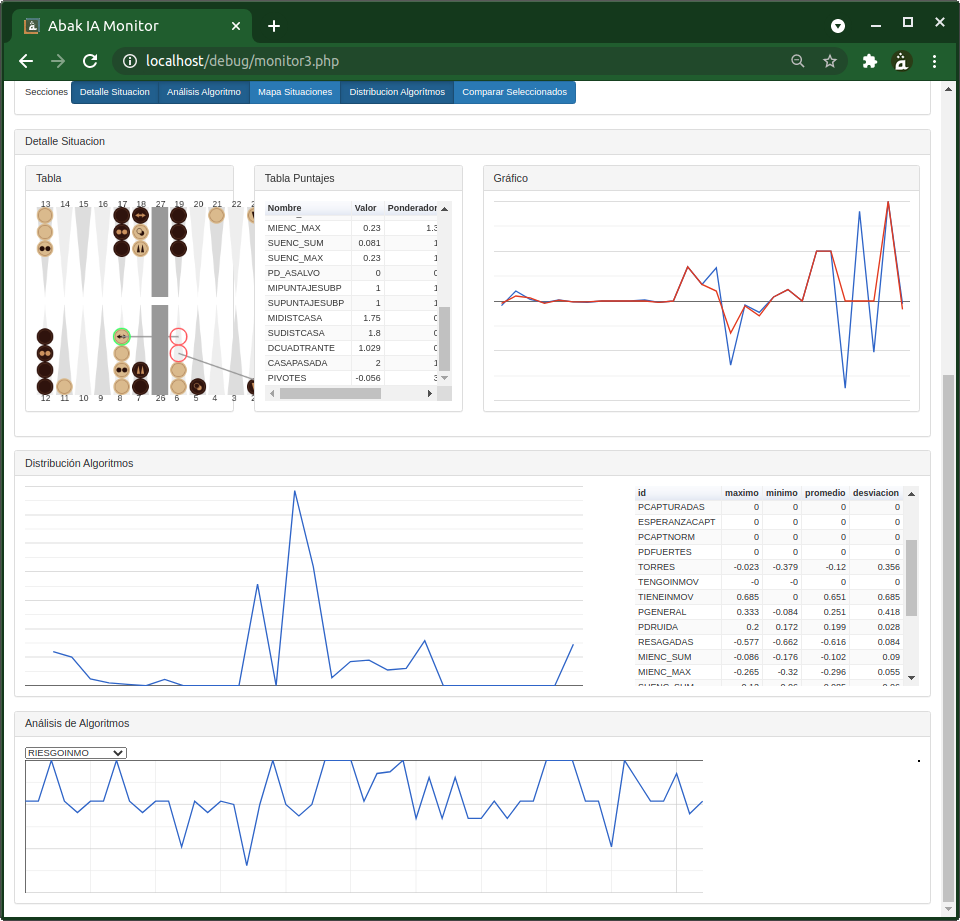
やがてかなり堅実な AI になりましたが、それ以上に完成度を上げるのはますます難しくなっていきました。コードの行数もシナリオも演算量も膨大で、コードレベルでのデバッグは重労働となり、係数の手作業の微調整も結果を生まなくなっていきました。
フェーズ 4、絶望
それでも私はもっと欲しかったのです。私は実際に Abak を遊ぶので、楽しめるだけの強い相手が必要でしたし、当時はそれを遊ぶ人間がほとんどいませんでした(この文章を書いている今でさえそうです)。
そしてこのアプローチには多くの欠点がありました:
- 現在の盤面位置から状態を計算し、その状態を使ってすべての有効手に対する分析アルゴリズムの係数を変えます。しかしその手自体が状態を変える可能性があるのに、エンジンはそれを考慮しません。
- 係数の手動微調整には途方もない時間が必要でした。楽しい時間ではありましたが、それでも膨大でした。
- 可能シナリオの多さゆえに、状態の計算は猛烈に難しく、常に欠陥のあるアルゴリズムでした。
- Game Equity を正確に計算することは不可能です。なぜならこのエンジンは各分析アルゴリズムに任意のスコア体系を持ち、最終スコアは勝率を反映せず、単に異なる盤面同士を比較するためのスコアとして機能するからです。絶対値というより相対値だと言えます。
フェーズ 5、覚醒
そしてある日、2018 年に Google が AlphaGo ニューラルネットワークで GO チャンピオンを破りました。世間は大騒ぎとなり、すばらしい新しいオープンソースの機械学習ライブラリも利用可能になり、家庭用 GPU を使って学習を高速化できるようになっていました。
もちろん私はニューラルネットワークについて多少は知っていましたが、自分で作ったことは一度もなく、正直に言って自分の能力を超える課題だと思っていました。
だから私は抗えませんでした。そして今や Expert レベルは、get-actions 部分を除いて、もう GOFAI エンジンでは動いていません。
でもこの物語はここで終わりです。
ここまで全部読んでくれたなら、私は驚いています。
この文章は、誠実な Abak Evolution チームにより SEO 目的で書かれました。
別名、Samy Garib。